JIRA 数据库核心表结构解析 (项目、事务、用户)
·2 分钟
目录
JIRA 作为业界领先的项目与事务跟踪工具,其背后有着相对复杂的数据库结构来支撑其强大的功能。了解其核心表结构对于进行数据分析、报表定制、系统集成或高级故障排查非常有帮助。
本文参考了 Atlassian 官方提供的 JIRA 数据库结构文档,并结合常见的核心概念(项目、事务、用户),对主要的表及其关系进行梳理和解读。
重要提示:
- 直接查询 JIRA 数据库应谨慎进行,尤其避免直接进行写操作,这可能会绕过 JIRA 的业务逻辑,导致数据不一致甚至损坏。
- 对于大多数数据交互需求,强烈建议优先使用 JIRA 官方提供的 REST API。
- 数据库结构可能随 JIRA 版本更新而略有变化。
以下是 JIRA 中关于项目、事务和用户这三个核心概念的主要数据库表关系图解(图片来源于网络或官方文档截图,仅为示意):
一、项目 (Project) 相关表 #
项目是 JIRA 中组织工作的基本单位。与项目相关的核心信息存储在以下关键表中:
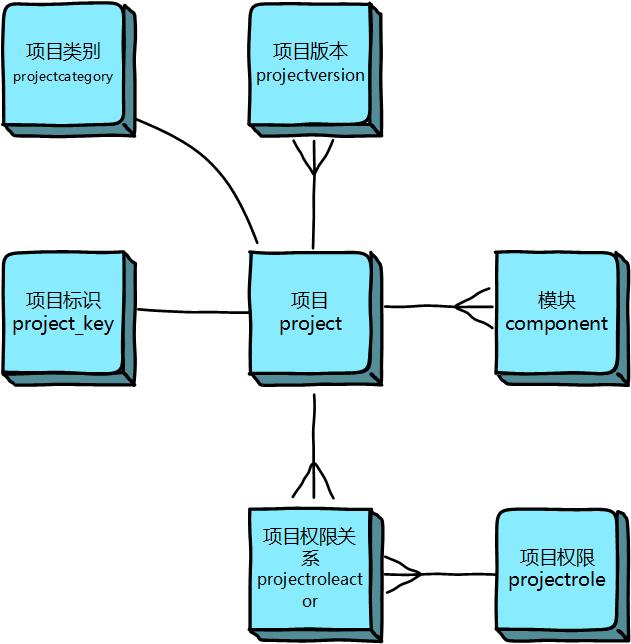
project: 存储项目的核心信息,如项目 ID (ID)、项目 Key (pkey)、项目名称 (pname)、负责人 (lead) 等。这是项目相关查询的入口点。projectcategory: 项目分类表,用于对项目进行分组管理。通过project.pcategory关联。component: 项目组件表,用于将项目下的事务按功能模块细分。通过component.project关联到project表。projectversion: 项目版本表,用于管理项目的发布版本。通过projectversion.project关联到project表。- 权限相关表(图中可能未完全展示):如
projectrole(项目角色定义)、projectroleactor(项目角色与用户/组的关联)、permissionscheme(权限方案)、nodeassociation(项目与权限/通知等方案的关联) 等,共同构成了 JIRA 灵活的权限体系。
二、事务 (Issue) 相关表 #
事务 (Issue) 是 JIRA 的核心,代表了工作项(如 Bug、任务、故事等)。事务相关的数据分散在多个表中:
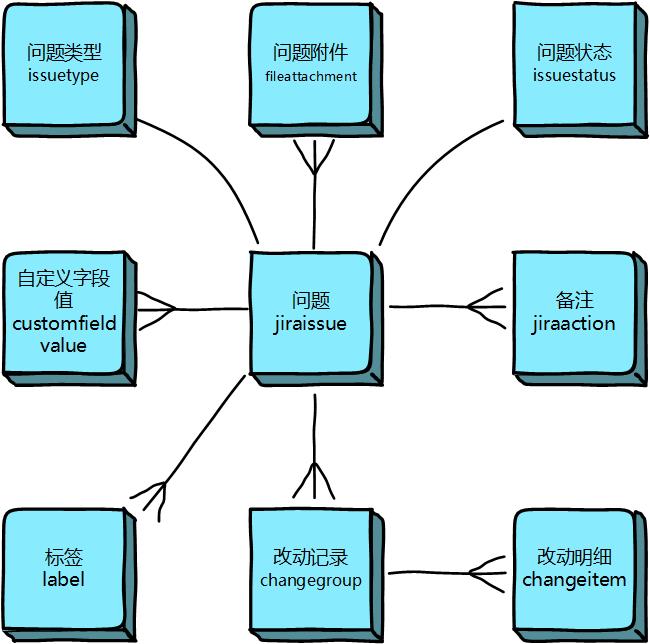
jiraissue: 最核心的表,存储每个事务的基本信息,如事务 ID (ID)、事务 Key (issuenum结合project.pkey构成如PROJ-123的 Key)、所属项目 (project)、报告人 (reporter)、经办人 (assignee)、事务类型 (issuetype)、状态 (issuestatus)、优先级 (priority)、解决结果 (resolution)、创建/更新时间等。issuetype: 定义事务类型(如 Bug, Task, Story)。通过jiraissue.issuetype关联。issuestatus: 定义事务状态(如 Open, In Progress, Resolved, Closed)。通过jiraissue.issuestatus关联。priority: 定义事务优先级(如 Highest, High, Medium, Low)。通过jiraissue.priority关联。resolution: 定义事务解决结果(如 Fixed, Won’t Fix, Duplicate)。通过jiraissue.resolution关联。customfield: 定义自定义字段。customfieldvalue: 存储自定义字段的值。通过customfieldvalue.issue关联到jiraissue表,通过customfieldvalue.customfield关联到customfield表。这是实现 JIRA 高度可定制性的关键。worklog: 存储工作日志(时间跟踪)信息。通过worklog.issueid关联到jiraissue表。jiraaction: 存储事务的操作历史记录,如评论 (actiontype = 'comment')、状态变更等。通过jiraaction.issueid关联到jiraissue表。- 关联关系表:如
issuelink(事务之间的链接关系)、nodeassociation(事务与组件/版本的关联) 等。
三、用户 (User) 相关表 #
JIRA 的用户和组管理通常依赖于底层的 Atlassian Crowd 库(即使是内置用户目录)。
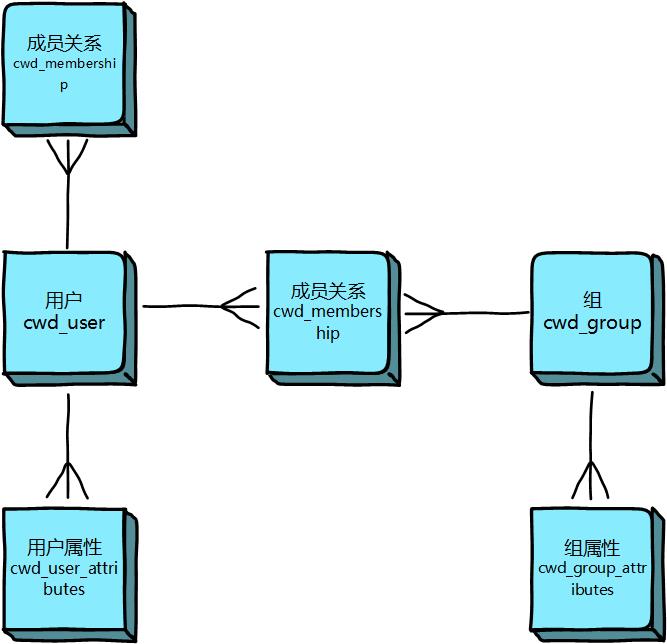
cwd_user: 存储用户的核心信息,如用户 ID (id)、用户名 (user_name)、显示名称 (display_name)、邮箱 (email_address)、活动状态 (active) 等。cwd_group: 存储用户组信息。cwd_membership: 存储用户和用户组的成员关系。关联cwd_user和cwd_group。app_user: JIRA 内部用于关联cwd_user和 JIRA 应用层用户概念的表,包含user_key(在 JIRA 中更常用的用户标识) 和lower_user_name。查询时经常需要将jiraissue表中的assignee或reporter(存储user_key) 与app_user关联,再关联到cwd_user获取详细信息。cwd_directory: 存储用户目录信息(如内部目录、LDAP 目录等)。
总结 #
JIRA 的数据库结构设计精巧但也相对复杂,反映了其功能的全面性和灵活性。理解上述核心表的用途和它们之间的关联关系,是进行 JIRA 数据相关工作的基础。
再次强调,除非绝对必要且完全理解其影响,否则应避免直接修改数据库。优先使用 JIRA 提供的 API 进行数据交互是更安全、更推荐的做法。希望本文的梳理能为你理解 JIRA 的数据存储提供一个清晰的概览。